【笔记】[NSDI'22] Efficient Scheduling Policies for Microsecond-Scale Tasks
Efficient Scheduling Policies for Microsecond-Scale Tasks
Sarah McClure (UC Berkeley), Amy Ousterhout (UC Berkeley), Scott Shenker (UC Berkeley, ICSI), Sylvia Ratnasamy (UC Berkeley)
背景
目前的数据中心运营致力于在支持微秒级延迟的同时尽可能提高 CPU 效率,已有的工作包括为应用程序静态或动态的分配 CPU 核心。但是由于大多数系统在进行应用间核心分配或应用内负载均衡的时候选择策略较为单一,因此他们在延迟和效率的权衡上表现不佳,尤其是处理短至 1 微秒的任务时。
主要贡献
作者团队基于仿真比较并探索了不同的调度策略,发现在负载均衡中 work stealing 的表现最好;核心分配中多种策略效果均不错,并且在处理短时长小任务时,静态核心分配的效果优于动态分配。作者团队同时证明在 Caladan 上实现最佳策略时,可以在不提高延迟的情况下提升 13-22% 的 CPU 效率。
小任务如何导致效率下降?
对于一般任务,调度造成的开销远小于其服务时长,因此调度开销占比较少;而对于小任务(1μs 量级)来说,调度开销占比就显得很大了,效率就会相应降低。
作者首先在 Motivation 部分提到了他们的实验,在 Arachne 和 Caladan 上分别跑对照任务(消耗所有剩余 CPU 周期)和小任务(memcached,他的平均服务时间就是 1μs 左右),并根据理论最佳吞吐量归一化实际吞吐量,以进行效率上的对比:
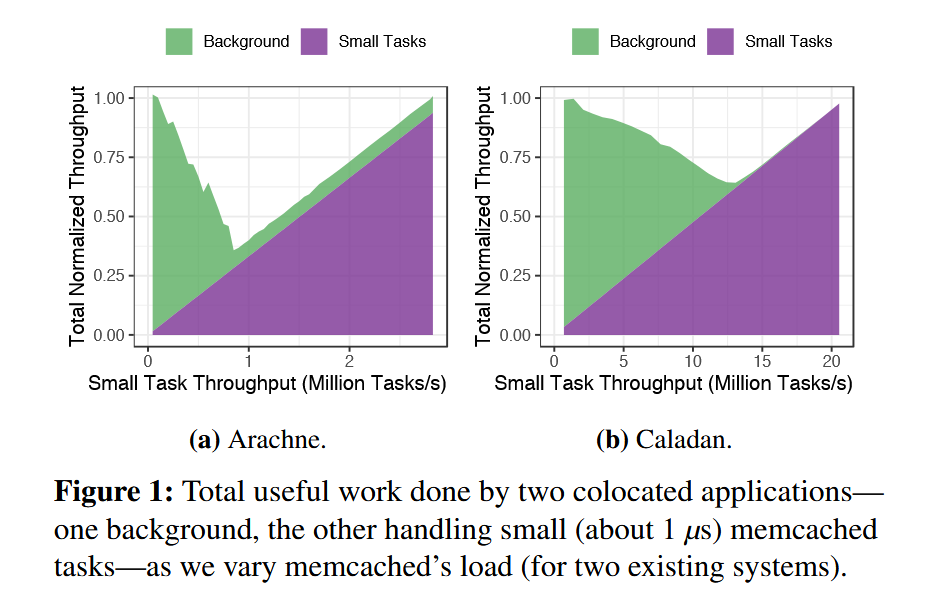
可以看出小任务会导致两个系统的效率大幅下降。作者提到这是因为为了保证小任务的低延迟(迅速处理),导致 CPU 效率的降低。
这里我个人的想法是在争用场景下(即图中效率下降明显段),两个应用之间的核心被细粒度的频繁来回调度(由于 memcached 任务的短时长),导致调度时间占比相较于服务时间明显提升,因此效率显著下降。疑问:为什么 Caladan 后期吞吐量几乎全部是小任务占用的情况下还是有一段达不到最佳效率?可能是对照任务仍然存在少量争用,但是几乎不占吞吐量。
策略评估
负载均衡策略
单队列
将所有任务放入一个共享队列,是一种理想化的负载均衡策略。显而易见的,对于队列的争用会严重限制吞吐率(估计效率和延迟也被严重影响)。Shinjku 和 RAMCloud 使用了这个策略,其中 Shinjku 吞吐量仅能达到 500w rps。
不做均衡
任务最先到达哪个核就谁来处理,没什么好说的。
队列选择
在任务创建时选择一个核心上的队列并安排任务,现有系统通常采用两选制,即随机选两个核,然后把任务安排给相对不忙那一个。每一个任务都会有选择开销,创建任务的核需要读其他核的队列的状态。
work stealing
当一个核空闲的时候,选择一个忙的核心然后转移他队列中一半的工作给自己。开销主要来源于检查其他核队列以及任务转移
工作卸载(shedding)
当一个核负载过重时,将任务卸载给其他核。工作卸载有多种实现,作者选取的卸载策略为当队列中有任务排队时间超过阈值的时候,当前核随机选择一个核心并让对方主动窃取自己一半的工作。开销方面包括选择核心以及发出/响应卸载请求、工作转移。
这里基本就能看出来 work stealing 最优,能确保每次均衡都是平衡最高值和最低值,也相对可控(队列选择就可能因为任务服务时间长短出岔子)。这里有一个疑问,work stealing 的任务初始如何分配?如果是按照任务最先到达哪个核分配,那有没有可能在吞吐量达到一定程度的时候,出现 stealing 停止的情况(大家都有活做,没有机会窃取),如果这个时候负载出现不均衡,是否还有其它保证延迟的措施?这种情况下是不是结合 work stealing 和 shedding 会好很多?
想了一下应该取决于数据包的转发策略以及应用程序自己的任务创建策略,如果是纯随机转发/创建,那基于巨大的任务基数,这种情况不能可能发生,而且任务积压只会是整体负载超负荷造成的,shedding 在这种情况下只会带来大量无效调度(互相推卸任务)。
核心分配策略
很难得出一种在保证一定尾延迟前提下又能得到最优效率(或者反过来)的分配策略,这属于 NP-hard 问题。下面是作者考虑的全部策略:
静态分配
为每个应用程序分配固定的核心数。静态分配的问题是无法应对数据中心常见的峰值负载,详见 Shenango。这里有个疑问是静态分配的一般策略是什么,还是说就是根据几个特定应用程序手动写死。
逐任务分配(Per-task)
为每一个新的任务分配核心,如 Fred 这样。开销来自核心的分配,除了核心全满的时候。(核心全满的时候是怎么分配的?Fred 又为什么这么做?)
基于排队分配
根据 runqueue 中任务的排队情况进行分配,指标包括线程、数据包、完成存储的次数或者他们的延迟。不同的系统也采取了不同的指标,如 Caladan 和 Shenango 根据所有核的队列(针对单一应用程序)的最大值,而 IX 和 Arachne 基于平均值。
基于 CPU 利用率分配
根据 CPU 核用于处理任务的时间比例或者空闲的核心数量进行分配。IX 和 Arachne 采用。
无事可做分配
当 CPU 核找不到活干的时候释放它,比如 work stealing 偷不到任务时(Shenango、Caladan、Go 语言)或者基于 Per-task 分配,当前核心完成了任务时(Fred)。
开销分析
负载均衡
负载均衡的开销和 CPU 架构有很大关系,比如 CPU 处理 cache miss 的速度,能否并行处理 cache miss 以及分支预测的准确率,其他方面还包括 cache coherence 等。
执行负载均衡的核心需要经历两次 cache miss,大约 60ns(Intel Haswell) - 400ns(志强 Phi),均衡中的另一个核心则是一次,大体就是 MESI 那一套。作为对照,Caladan 的一次 work stealing 负载均衡需要 120ns。
值得注意的是,作者测试了 Intel Skylake 的单核并行 cache miss 极限,大约是 10 - 12 个。
核心分配
核心分配的开销主要和策略有关,至少有一次 IPI,大约 1993 个周期,1μs 左右。Shenango 分配空闲核是 2.2μs,繁忙核是 7.4μs,Arachne 分配一个核是 29μs.
繁忙核缓存比较乱,寄存器存了上下文,还有可能处在不能打断的运行部分(比如临界区),所以慢很多。
仿真设计与实现
参数设置和建模:
负载均衡跨核通信开销:100ns 核心分配开销:5ns
模型假设每个核心有一个本地队列,不区分数据包队列和线程队列,也就是任务会随机的从任何一个核上出现。模型不支持任务抢占,不过提到了这方面可以扩展。
单队列和不做均衡
开销统一建模为 0,因为确实没有负载均衡操作。
队列选择
使用两选制,每个任务产生一次 100ns 的负载均衡开销(去往目标队列)。
work stealing
每次检查其他队列 100ns 开销,窃取工作也是 100ns 开销。
工作卸载
卸载工作产生 100ns 的开销。
个人想法
这一篇主要通过通过仿真证明了为什么 work stealing 是最好的负载均均衡策略,以及处理一微秒级别小任务的时候,静态核心分配会比动态更好。但是由于内容主要是描述如何进行仿真建模和论证,读起来实在坐牢,确实不好归纳,知识点也非常多,有非常多的疑问,因此打算先放一放,后面再细读。